Closed-loop replanning with JaxPlan.#
This follow-up example provides another way to do closed-loop control in JaxPlan. Starting with the initial state of the system, optimize the action-fluents over a short lookahead horizon (e.g. 5 decision steps), then take the best immediate action from the plan and let the system evolve. Then repeat the process again, taking the best action from the new plan, and so on. This technique is called replanning in the planning literature, which is quite similar in flow to model-predictive control (MPC) where we obtain the dynamics model from the RDDL description.
Start by installing the required packages:
%pip install --quiet --upgrade pip
%pip install --quiet pyRDDLGym rddlrepository pyRDDLGym-jax
Note: you may need to restart the kernel to use updated packages.
Note: you may need to restart the kernel to use updated packages.
Import the required packages:
import warnings
warnings.filterwarnings("ignore", category=UserWarning)
from IPython.display import Image
import os
import pyRDDLGym
from pyRDDLGym.core.visualizer.movie import MovieGenerator
from pyRDDLGym_jax.core.planner import JaxBackpropPlanner, JaxOnlineController, load_config_from_string
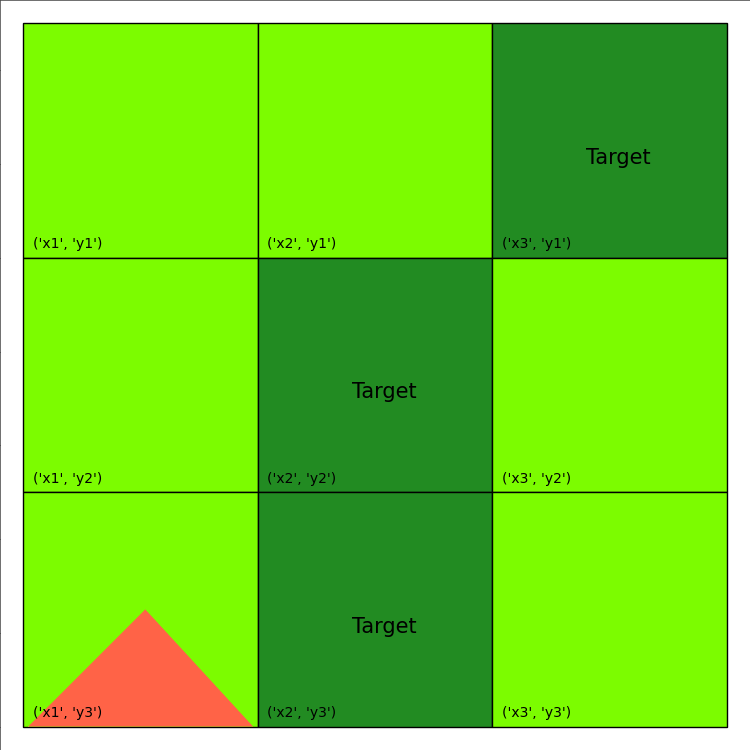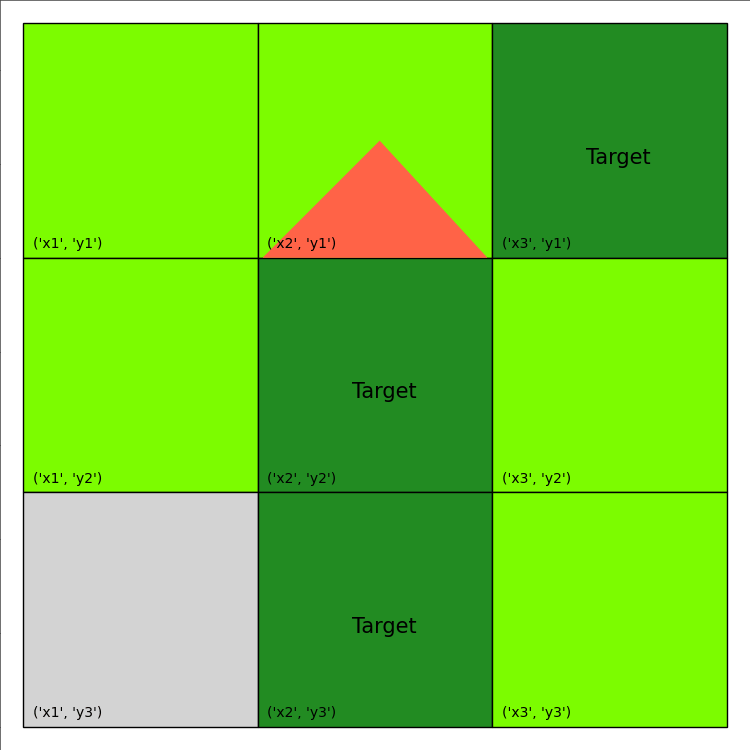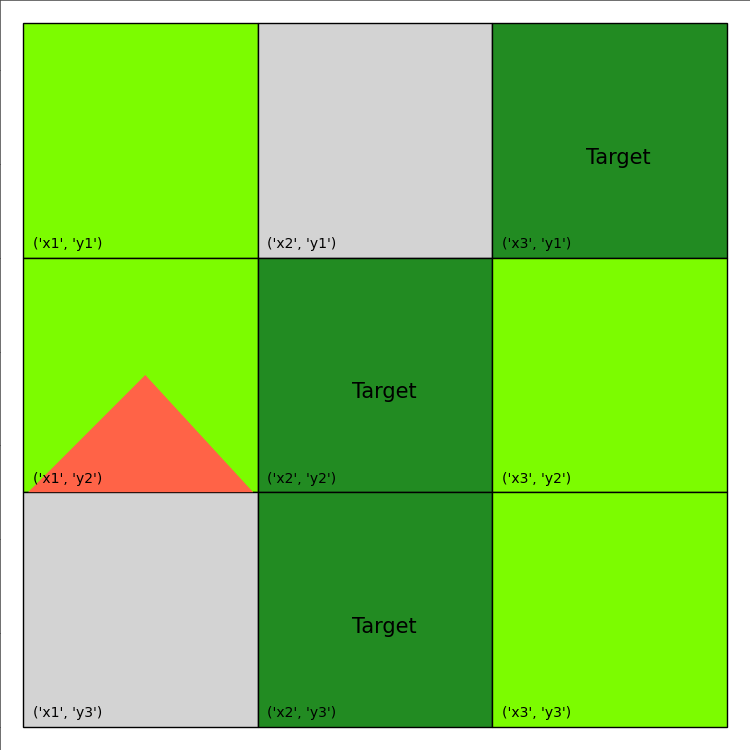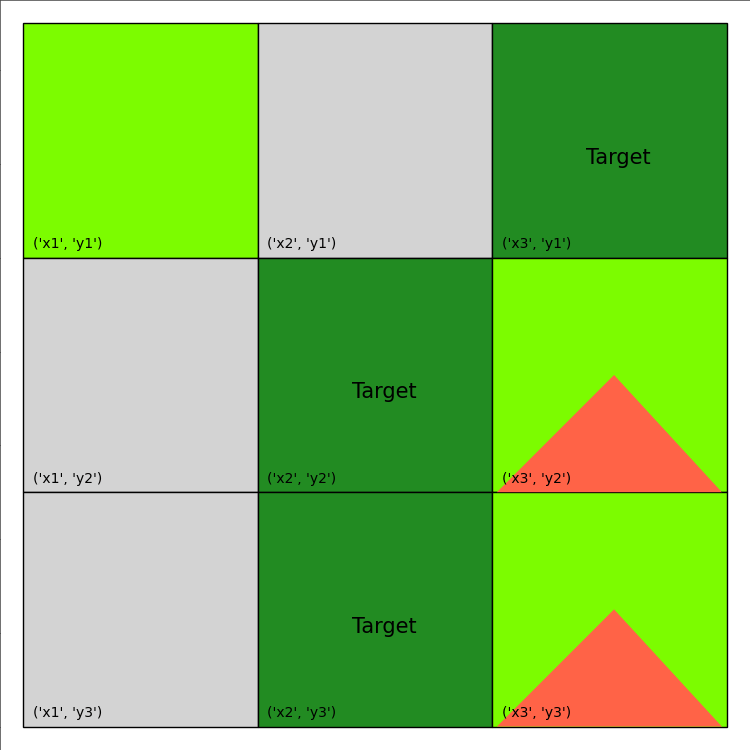
We will again optimize the stochastic Wildfire problem from IPPC 2014, noting again the use of the vectorized option:
env = pyRDDLGym.make('Wildfire_MDP_ippc2014', '1', vectorized=True)
The config file is similar to the open-loop examples, except we also specify the rollout_horizon parameter to indicate how far ahead we search during optimization:
config = """
[Compiler]
sigmoid_weight=100.0
print_warnings=False
[Planner]
method='JaxStraightLinePlan'
optimizer_kwargs={'learning_rate': 0.1}
pgpe=None
rollout_horizon=5
[Optimize]
key=42
"""
planner_args, _, train_args = load_config_from_string(config)
We now initialize and run our controller. We will set train_seconds to 1 to indicate that we want to optimize for 1 second per decision time step:
planner = JaxBackpropPlanner(rddl=env.model, **planner_args)
agent = JaxOnlineController(planner, print_summary=False, print_progress=False, train_seconds=1, **train_args)
Notice that no optimization is done before calling the evaluate function, because the replanning method will only optimize when it actually begins interacting with the environment, e.g. it observes the current state, finds the best action, executes it in the environment, then waits for the state to transition and begins again.
Let’s assign a visualizer so we can keep track of the behavior of the planner in real time. Then we just call evaluate() to actually do the planning:
if not os.path.exists('frames'):
os.makedirs('frames')
recorder = MovieGenerator("frames", "wildfire", max_frames=env.horizon)
env.set_visualizer(viz=None, movie_gen=recorder)
print(agent.evaluate(env, episodes=1, render=True))
env.close()
Image(filename='frames/wildfire_0.gif')
{'mean': np.float64(-80.0), 'median': np.float64(-80.0), 'min': np.float64(-80.0), 'max': np.float64(-80.0), 'std': np.float64(0.0)}